
Google Research, Robotics at Google, Waymo LLCによる論文、Unsupervised Monocular Depth Learning in Dynamic Scenes(arxiv)を読み込むことになったので、ついでにここにまとめようという魂胆。日本語まとめとしては、Qiitaの記事が2つ見つかります(Qiitaの記事1, Qiitaの記事2)。1には、式の解釈でかなりお世話になりました!2は、わかりやすく全体を俯瞰するのにお世話になりました!
まとめるというアウトプットによって、自分の理解度もあがるのです(/・ω・)/
(2021/11/17追記:もう一回この論文をしっかり理解&復習するため、一部加筆修正)
Contents
論文まとめ:Unsupervised Monocular Depth Learning in Dynamic Scenes
- 著者:Hanhan Li1 Ariel Gordon1,2 Hang Zhao3 Vincent Casser3 Anelia Angelova1,2 (1Google Research 2Robotics at Google 3Waymo LLC)
- 出典:CoRL2020(Conference on Robot Learning)
- ArXiv: https://arxiv.org/pdf/2010.16404.pdf
- github: https://github.com/google-research/google-research/tree/master/depth_and_motion_learning
どんな研究か
- 単眼RGBカメラで撮影した2枚の画像から、depth, ego-motion(カメラ自身の動き), object motion(シーン内の移動物体)を推定
- 押ポイント:従来必要だった移動物体の情報(bounding boxやsemanticな情報など)を用いる必要がない
- semanticな情報を外部モジュールで推定していることが多い
- キモ:シーンにおける事前知識を正則化として用いる点
- カメラパラメータそのものを学習&推定可能(youtubeのデータセットにはカメラパラメータはない。カメラパラメータを学習している。実装を見ると、カメラパラメータがある場合はそれを用いることも可能)
単眼カメラで撮影したビデオフレームから2フレーム(画像左から二番目)を用いて、Depth(深度画像,画像左側)、ego-motion(カメラ自体の動き)、Object motion map(動画内のオブジェクトの動き,画像右から二番目)を推定する。ego-motionとObject motion mapを合わせて、Motion mapを計算

従来の手法では、RGBのペアに加えて外部モジュールで推定したsemanticな情報や動的物体のbounding boxなどの情報が必要だった。この研究では、それらの追加情報の代わりに、シーンのほとんどは静的&動的物体は剛体だから物体の移動は一定(同じ物体のピクセルの移動は一定:車などは全ピクセルが同じ方向に同じ速度で動いていると見なせる。人を剛体と仮定するのは微妙に思えるが。。。)だから全体としてスパースである(静的物体のピクセルは0, 移動物体のピクセルは周囲と同じ値)、という事前知識を正則化として用いることで学習できたという点が押ポイント。motion mapのほとんどの場所は値が0であり、移動物体場所もほとんど一定の値である(例えば、人の場所と車の場所で色が分かれている)。
そもそも、教師なし単眼深度推定は何に基づいて深度推定ができているのか?
この手法では、時系列的に連続する2枚のRGB画像を用いている。前のフレームで深度、カメラ自身の動き(カメラパラメータ、内部パラメータも含む)が正しく推定できているならば、その推定した深度とカメラパラメータを用いて次のフレームに変換可能(warp可能)であるはず。
その変換した画像と次のフレームとの差を見ることで、深度とカメラパラメータが正しく求まっているかを知ることができる。(差が大きいならば、推定されている深度とカメラパラメータがおかしい)
これをconsistency lossと呼ぶ。推定が上手くいっているならば全体として一貫性が保たれているはずという事に基づいている。
これを主な基準として単眼深度推定を行っている。この手法では、更に先述の制約(事前知識による正則化)を使うことでいろいろ良くなったよーという研究。
アブスト翻訳
単眼の画像整合性(monocular photometric consistency)を唯一の基準として、Depth(深度画像)、ego-motion(カメラ自身の動き)、シーンにおけるオブジェクトの高密度3D平行移動の推定を同時に学習する方法を示す。この明らかに劣決定の問題は、3D平行移動に関する次の事前知識によって正則化できることを示す。シーンのほとんどが静的であり、剛体の移動に対しては一定であるため、スパースである。この正則化だけで、セマンティック入力を必要とするメソッドを含む、動的環境における従来研究で達成された精度を超える単眼深度予測モデルを学習するのに十分であることを示す。
イントロ
カメラ画像から三次元の幾何学情報やオブジェクトの動きを理解することは、ロボット工学や自動運転で重要な課題。光学カメラ(通常のカメラ)のみでこれらの情報が予測できるのは非常に安価である。(3次元情報をセンサ値として得ようと思うとLiDARなどの高価なセンサが必要)
三次元情報を単眼カメラから得ようとする問題は、ill-posed problem(不良設定問題)であり、多くの研究ではシーンの事前知識を用いる。depth predictionはセンサーによって教師がつけられるが、3D motionに関してはラベル付けされているものは少ない。ラベル付けされていない単眼カメラのビデオ自身に依存するself-supervised method(自己教師あり学習)が最近注目を集めている[6, 7, 8, 9, 10, 11, 12, 13]。
深度推定の自己教師あり学習は、SfM(Structure from Motion, カメラ画像から幾何学構造を復元する研究分野)に基づいている。同じシーンを2つの異なる位置から見ると、各ピクセルに正しいdepthがつけられているときのみ、見えの一貫性が保たれてカメラの動きが正しく推定される。よってこれらの方法は、テクスチャがない領域やocculusion(隠れ)など、SfMにおける多くの課題に影響される。2つのフレームで動的物体があった場合、4つの未知変数(深度、x,y,z)があるため、エピポーラ幾何の制約を明確にするには多すぎる。そのため、自己教師あり学習は追加情報に依存する。
1つ考えられる追加情報は、意味情報(semantics)である[12]。semantic segmentationなどで車両や人などの動的物体がわかれば各オブジェクトの動きを個別に推定できる。しかし、これらはシーンに存在するすべてのクラスがセグメンテーションできるという補助モデルがあるかどうかに依存している。
他のアプローチでは、種類の事前知識を用いている。例えば[13]では、自動運転のシーンを考えて、見える車は全て同じ速度で動いていると仮定して、2つのフレームで変化していない領域は別の車であるという事前知識を利用している。これはKITTIデータセットを使う場合には一般的なやり方であり深度推定が大幅に改善するが、特定のシーンに限定されている。また、optical flowをdepthと同時に学習するというやり方[14]もあるが、stereo cameraを用いている。
この手法のcontribution(貢献)は、以下のような従来と異なる手法でdepth, ego-motion, motion mapをmonocular videoのみから推定したことである。
- monocular video以外の補助情報を利用しない。semantic情報、stereoなどの情報は使わない。
- オブジェクトの動きを剛体物体の移動として近似する
この手法のキモは、1/2(二分の一) normに基づいた、 2つフレーム間の移動を考えるための新しい正則化によって、上記の問題を解決することにある。
この手法では、ネットワークが2つのフレームから密な三次元移動フィールドを推定する。3次元移動フィールドは、カメラに対する背景の平行移動とオブジェクト自体の移動に分解できる。別のネットワークが各ピクセルのdepthを推定し、ピクセル当たりの予測値は4種類(depth, x,y,z)になる。推論時には、depthは単一のフレームから推定され、移動フィールドは2つのフレームから推定される。
単眼カメラのみを使用することを目的としているため、この問題には大きな正則化が必要である。それは次の事前知識に従う。
- ほとんどのピクセルは背景や動かないオブジェクトに属するのでスパースである
- 剛体全体で一定である
この手法を動的物体を含む4種類のデータセットで性能を評価した。Cityscapes, Waymo Open Dataset, KITTIにおいて、unspervised depth predictionのSOTAな手法を確立した。更に、様々な環境で手に持ったカメラを使って歩きながら撮影されたpublicなYouTube動画を用いて学習・評価を行った。その結果を以下の図に示す。

関連研究
structure from motion and multiview stereo
従来手法でhは二枚の画像内の対応点を識別して、エピポーラ幾何学によって深度を推定するが、これらの手法はまばらな深度画像になる。(いわゆるステレオカメラの話?)[21]が詳細にこの分野についてサーベイしているらしい。
Depth Estimation
Deep Learningによる手法は、LiDARなどの情報を教師として学習する。最近では、古典的なコンピュータビジョンの手法と組み合わせて、depthとego-motionを学習している。深度推定をより正確にするために、学習にステレオ入力を使用する研究がいくつかある。オンラインで深度センサ情報を用いて補完する方法もある。
Depth and Motion
カメラとシーン内のオブジェクトの双方が動いている場合、見えの一貫性を保つにはカメラと個々のオブジェクトの両方の動きを推定する必要がある。単眼ビデオから深度、カメラの動き、オブジェクトの動きを同時に学習する方法がいくつか提案されている。
我々の手法は、動的なシーンで教師なし学習を行うための一般的な方法を提供する。オブジェクトの動きやステレオを推定するために、オブジェクトをsegmentする必要はない。optical flowを使う方法やocculutionを推論するこれまでの手法とは異なり、3Dでモーションを直接推定するため、深度予測の精度が向上する。
手法

自己教師あり学習によって、単眼ビデオの隣接するフレーム(Ia, Ib)からdepth map D(u, v), ego-motion(カメラ自身の動き), object motion(動的物体の推定)を同時に学習する。
depth networkは2つのフレームIa, Ibに個別に適用されて、depth map Da, Dbを得る。2つのdepth mapは元の画像とともにmotion networkに入力されて、カメラ自身の動き(Egomotionの6つのパラメータ)とObject motion mapを推定する。motionとdepthの推定値が得られたら、もう一方のフレームを計算する。ここから画像内に赤背景で示される3つのloss(Depth reg. loss, Motion reg. loss, Consistency loss)を計算する。
Depth Network
参考文献[6]のencoder-decoderアーキテクチャを用いた。最終層の活性化関数をdepth推定用にsoftplus activationに変更。各層でreluを適用する前に、randomized layer normalization[11]を適用
randomized layer normalization
[11]の深度画像推定では、Batch normalization(BN)を使っていたが、training modeで推論しないと精度が悪化する問題があった。BNのtest modeでは、正規化に用いる平均と分散が固定されるため、training modeと同じく入力データのみに従って正規化した方が良いという仮説が立つ。また、バッチサイズが増えることでも精度が悪くなっていた。これは、バッチサイズが増えると平均と分散が安定しすぎるためであるという解釈をした。これらの解決のために、Layer Normalizationで計算される平均と分散に明示的にノイズを加えることで、推論時の精度向上が見られた。
詳しくはこちらのQiita記事を参照
Motion Network
参考文献[11]のものとほぼ同じ。入力がRGBの3次元に加えて、channel方向にDepthを加えた4次元のフレームという点が異なる。(なんだかよくわからないので[11]をちゃんと読まないとわからなそうなのと、重要ではなさそうなので飛ばす)
Loss
以下の3つのlossの合計になっている
- motion regularization
- depth regularization
- consistency regularization
motion/consistency regularizationは2回適用される。(画像ペアの正順と逆順で2回)depth regularizationは各画像に1回。
Motion Regularization
この論文で最も重要なところ。
- group smoothness

- 移動領域内の変化を最小に抑えて、移動物体全体でmotion mapの値が一定になるようにする。動的物体が剛体であるという仮定に基づく
- sparsity loss
- L1正則化よりもスパース性が強力。
の2つで構成される以下の式に従う。α、βはハイパーパラメータ。
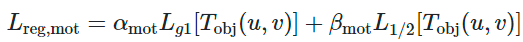
group smoothness
以下の式で定義される。T(u,v)は、移動物体の移動ベクトルのマップ。u, vはマップ上における座標。
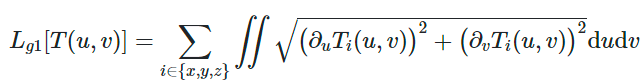
動的物体が剛体であると仮定すると画像内の同じ物体のピクセルは同様に動く、という事前知識に基づいて、移動ベクトルマップの横方向、縦方向(u,v方向)の変化の絶対値の総和を損失としている。
つまり、画像内(移動ベクトルマップ内)で隣り合うピクセルとの差が少ないほど良いということを表す。背景と移動物体との境目だけ変化量が大きくなって、それ以外の変化は少ないことが理想とする損失。
sparsity loss
以下の式で定義される。<|Ti|>は、Ti(u,v)の平均値。

![]() は、以下のグラフのようにTiの値が小さいところではL1に漸近して、大きいところではその働きが弱くなる性質になる。
は、以下のグラフのようにTiの値が小さいところではL1に漸近して、大きいところではその働きが弱くなる性質になる。
グラフはsupplementary materialより。青がL1=x, 赤がL1/2=2*√(1+x) -2のグラフである。値が小さいところではL1に近くなり、大きいところではL1よりも影響が弱くなる。L1/2に-2がついているのは比較のためのバイアスであり、reguralizationには影響しない。
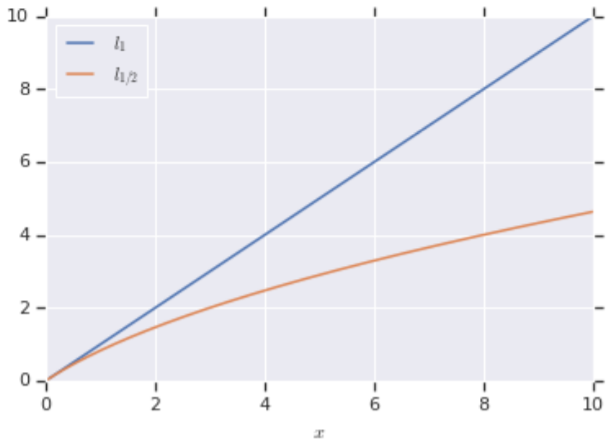
L1よりもスパース性が強くなるらしいが、その点についてが良くわからなかった(´・ω・`)
スパース性が強いという事は、移動物体のところは一定の値を持って、背景は0になるということを表現しやすい。
Depth Regularization
Godardらの手法[27]で使われているedge-aware smoothness regularizationを用いる。
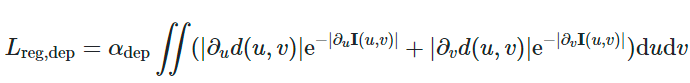
∂d(u,v)なので、深度画像のu,v方向の変化が少ないほど良いとする正則化。これに加えて、exp(-|∂I(u,v)|)はRGB画像の色変化が少ないと大きく、色変化が多いと小さくなる。これは、色変化が多いところは違うオブジェクト、色変化が小さいところは同じオブジェクトであるという解釈。そのため、同じオブジェクトでは深度画像の変化量は小さくしてほしいという正則化になる。
Consistency Regularization
以下の2つで構成される。深度を求めるためのメインのlossになるもの。実際に、実装を見るとデフォルトの各loss値の重みパラメータはSSIMに関するloss(以下の式のβ_rgb)が他のパラメータに比べてかなり大きくなっている。
- motion cycle consistency loss
- カメラのモーションと画像ペアの一貫性に関するloss
- occlusion-aware photometric consistency loss
- occulusionの考慮と、画像の類似度に基づいたloss
motion cycle consistency loss
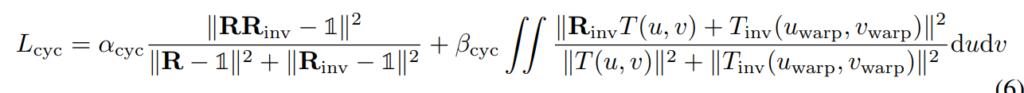
frame A→ frame Bの変換と、frameB → frameAの変換は、逆の変換になるという発想がcycle consistency loss。
第一項目は回転について考えている(Rはrotation matrix)。分子の|R・Rinv – I|は、AからBへの変換RとBからAへの変換Rinvが同じであれば単位行列になるはずという事に基づいている。
第二項目は移動と回転両方を考慮している。これも、うまく計算できていれば、分子の|Rinv・T(u,v) + Tinv(uwarp, vwarp)|がゼロになるはずという事に基づいている。
詳しくはQiitaの記事を参考に。
occlusion-aware photometric loss
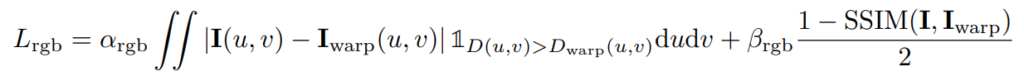
基の画像とwarpした画像(推定されたカメラ行列で変換した画像)のL1loss(第一項)とSSIM(古典的な画像の類似度の指標)(第二項)
SSIMについては、こちらを参照。輝度、コントラスト、構造の3点で画像の類似度を表す指標。
![]() はGordon[11]で提案された、occulusion問題に対応するためのマスク。warpした画像の結果よりも実際の画像のdepthが前にあるならば|I-I_warp|を計算する。連続する2枚の画像で手前にあるオブジェクトの関係で隠れている場所(occulusionが起きている箇所)は計算しない。そもそも片方の画像で隠れてしまっているので、損失として計算するのはノイズになってしまうためと思われる。
はGordon[11]で提案された、occulusion問題に対応するためのマスク。warpした画像の結果よりも実際の画像のdepthが前にあるならば|I-I_warp|を計算する。連続する2枚の画像で手前にあるオブジェクトの関係で隠れている場所(occulusionが起きている箇所)は計算しない。そもそも片方の画像で隠れてしまっているので、損失として計算するのはノイズになってしまうためと思われる。
実験
- Cityscapes, KITTI, Waymo Open Dataset, YouTubeから集めたビデオの4つのデータセットで実験を行った
- 全てのデータセットで、ハイパーパラメータは同じ
- depth networkのenocder partをImageNetでpretrain
- depth networkはNVIDIA V100で480×192pxで1枚当たり5.3msecの推論速度(関連研究で最速)
Cityscapesの結果

δ<xのやつは、正答値の1/x ~ xの間に推定値が含まれている割合
他手法に比べて良いですね!意味情報を使う手法よりも優れた結果になる。
δ<1.25などの指標は、推定値と正解値の比が1.25~1/1.25の中に納まるピクセルの割合を意味する。高いほど良い指標(どれだけ正解に近い推定値があるか)左から1.25, 1.25^2, 1.25^3なので、左側ほど厳しい評価指標。
比較実験

![]() の方がL1よりも良い結果になる。また、動的物体にマスクを付加する外部モジュールを追加しても(4行目)深度の推定精度にあまり変化はない。
の方がL1よりも良い結果になる。また、動的物体にマスクを付加する外部モジュールを追加しても(4行目)深度の推定精度にあまり変化はない。
その他のデータセット
KITTIでは他のSOTAな手法と同等、Waymo Open DatasetでもSOTAな手法より良い。また、Waymo Open Datasetではマスクなしでも他手法より優れた結果であるが、(Cityscapesの時と違い)マスクを追加することでさらなる改善がみられる。
YouTubeから収集した動画でも定性的に良い結果を得ることができた。YouTubeの動画はカメラ情報も深度のアノテーションも存在しないが、学習可能。
おわり
おわり!
No responses yet