機械学習の評価指標にTPとかFNとかRecallとかIoUとかなんとかかんとか。いっつもこんがらがるので自分なりにわかるようにメモ書き!(^^)!
画像処理ばかり扱ってるので、YOLOみたいな物体検出タスクやSemantic Segmentationを想定してます。あしからず(*ノωノ)
Contents
TP, TN, FP, FN
それぞれ次の言葉の略
- TP: True Positive
- TN: True Negative
- FP: False Positive
- FN: False Negative
表で説明すると以下のような感じ
| 真値が正 | 真値が負 | |
| 予測が正 | TP | FP |
| 予測が負 | FN | TN |
言葉としては、「合ってる(True)/間違ってる(False)」「 正(Positive)/負(Negative)」 という表し方になります。
前半のTrue/ False でその予測結果が正解か間違いか、後半のPositive/ Negative で予測は正か負か
。。。言葉じゃ伝わらなそう((+_+))
図で説明する
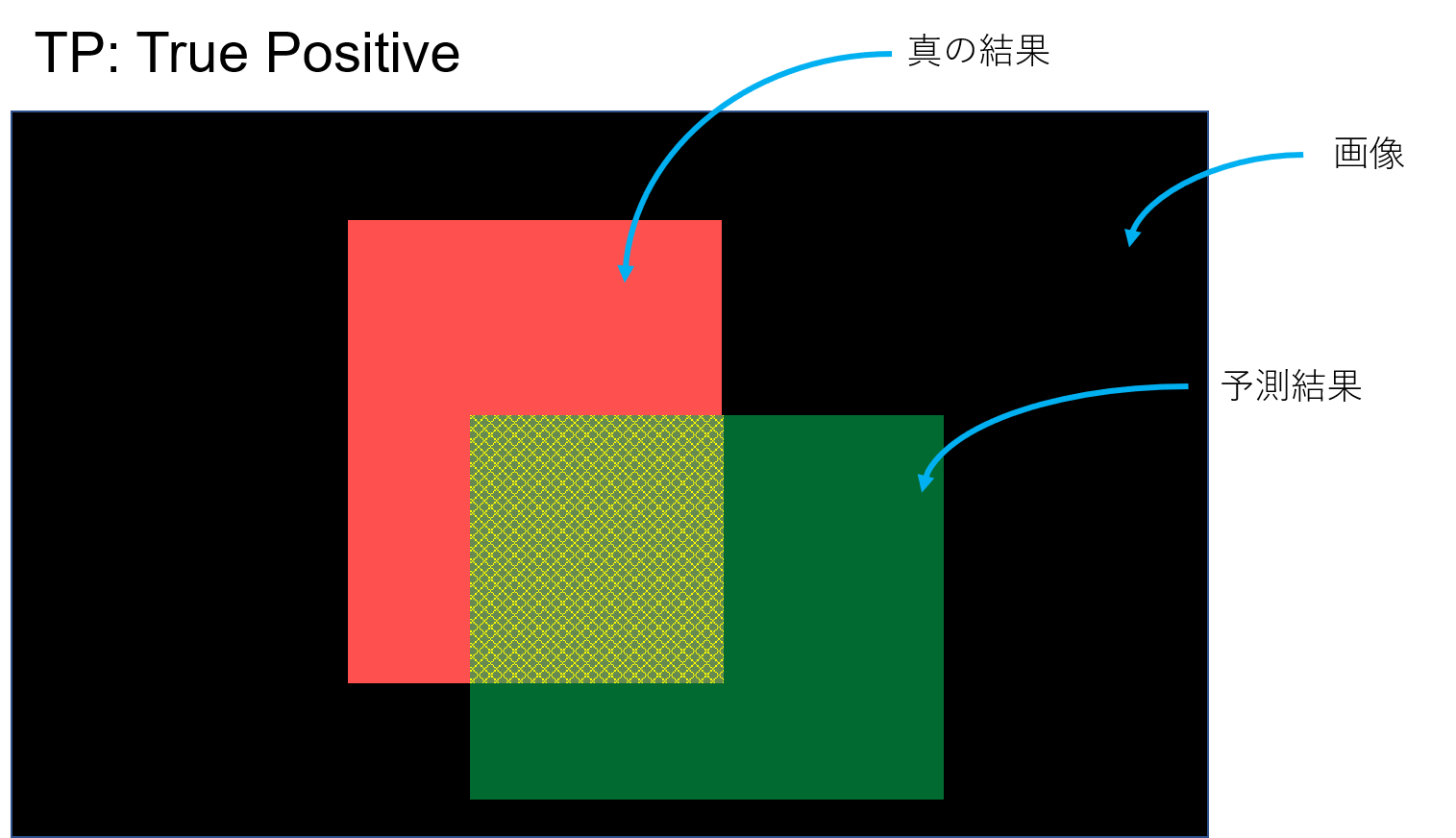
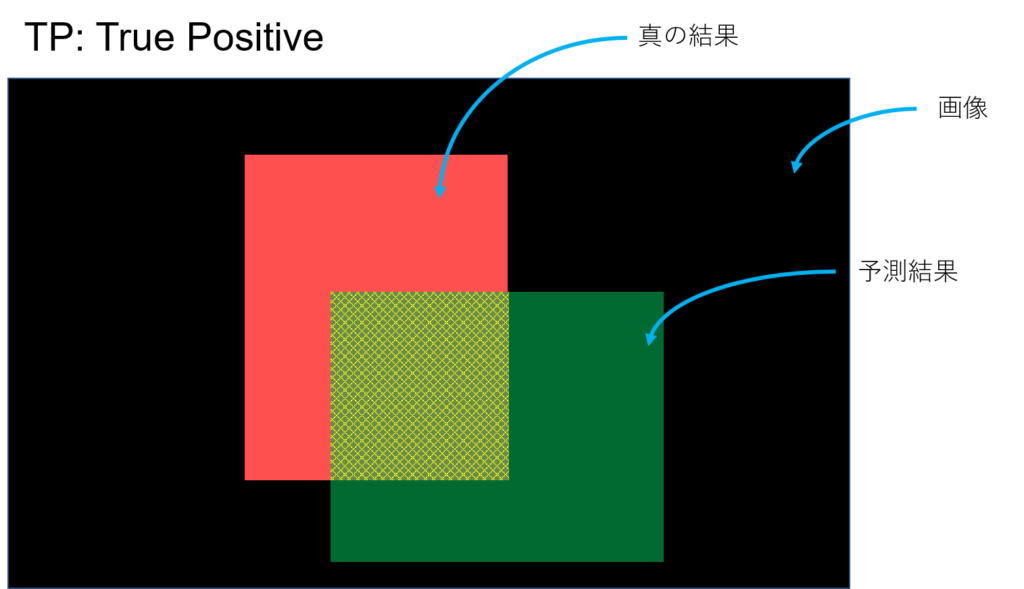
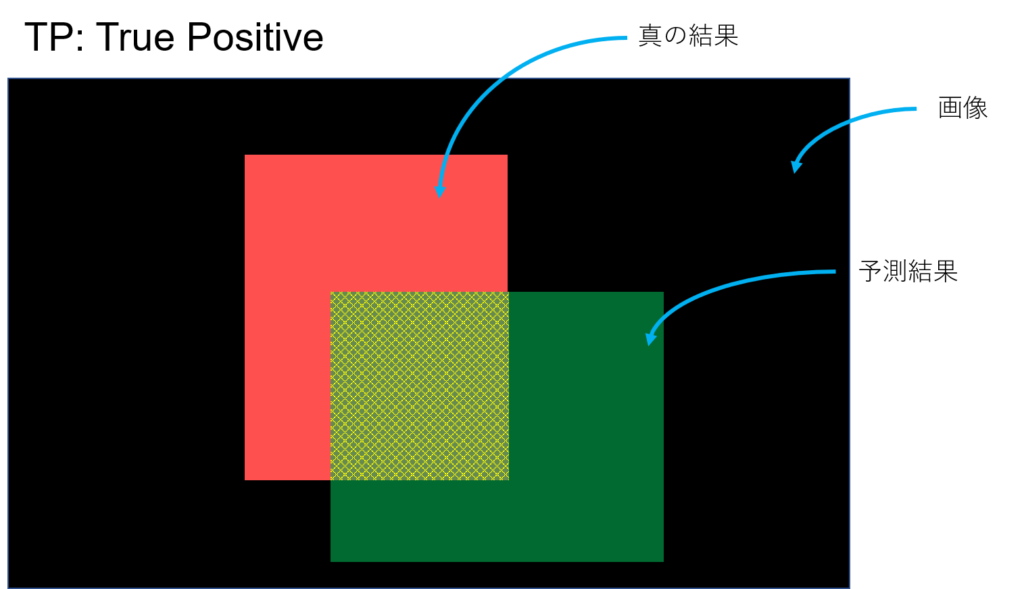
こんな風に予測したとする。YOLOとかの物体検出とかSemantic Segmentationみたいなタスクのイメージ。予測してほしい真の結果が赤、予測結果が緑。黒はなんらかの画像(背景)、つまり予測してほしい領域でもなく、予測結果でもない領域。
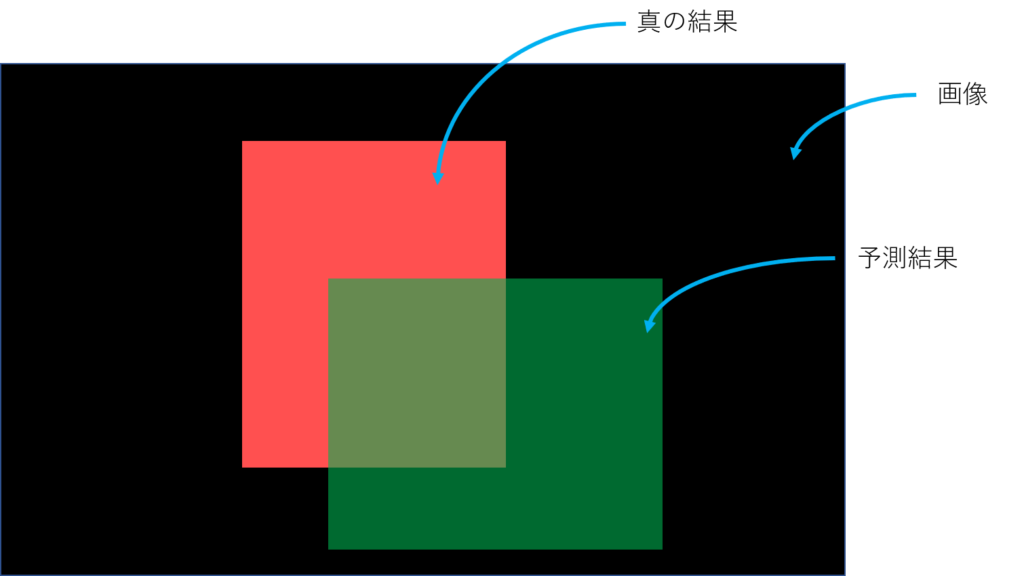
TP, TN, FP, FNはそれぞれ次のような感じ
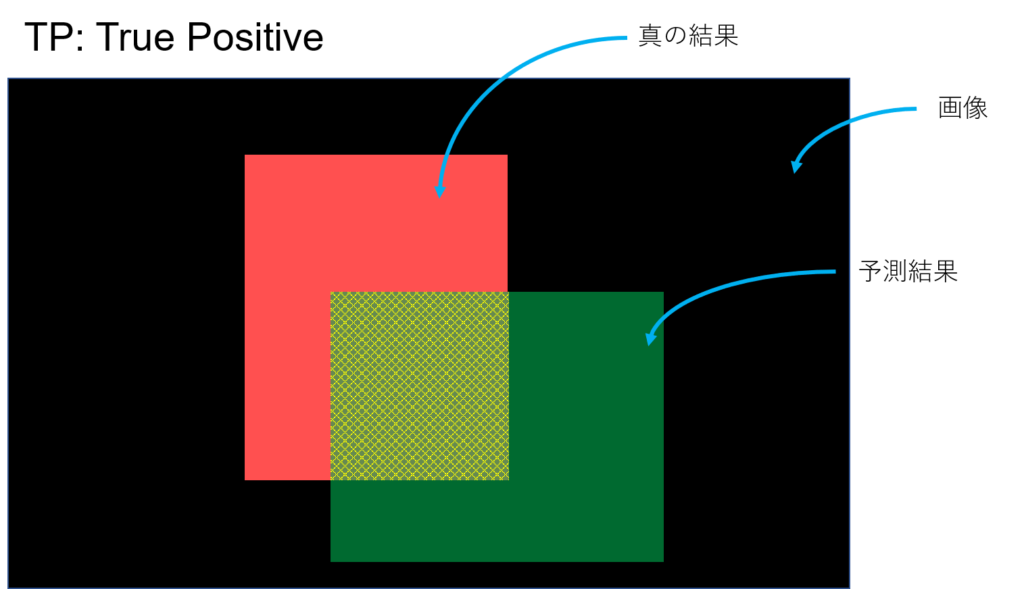
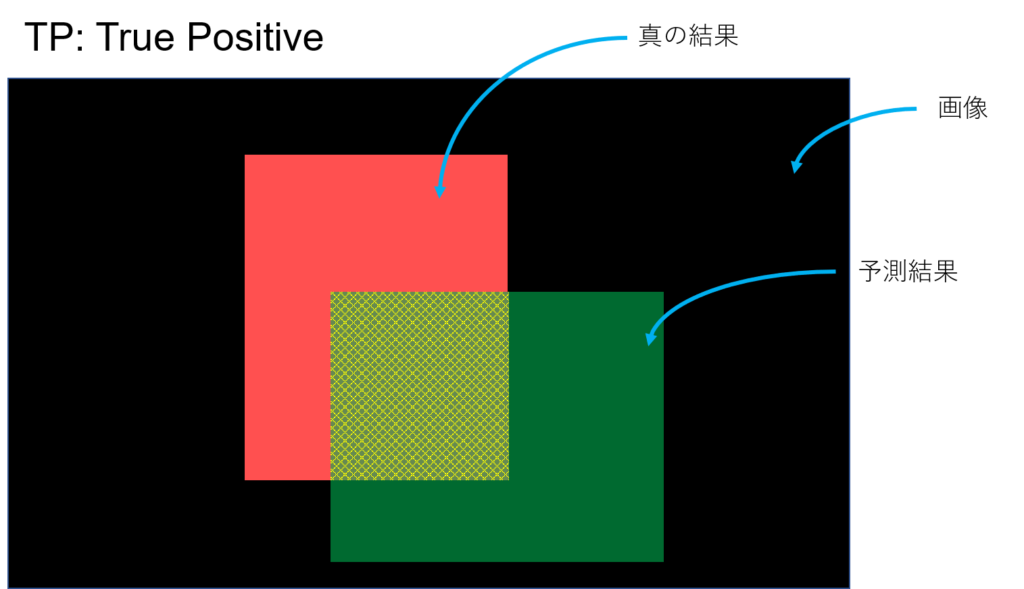
正(Positive)であるといったけど、それは合っている(True)。
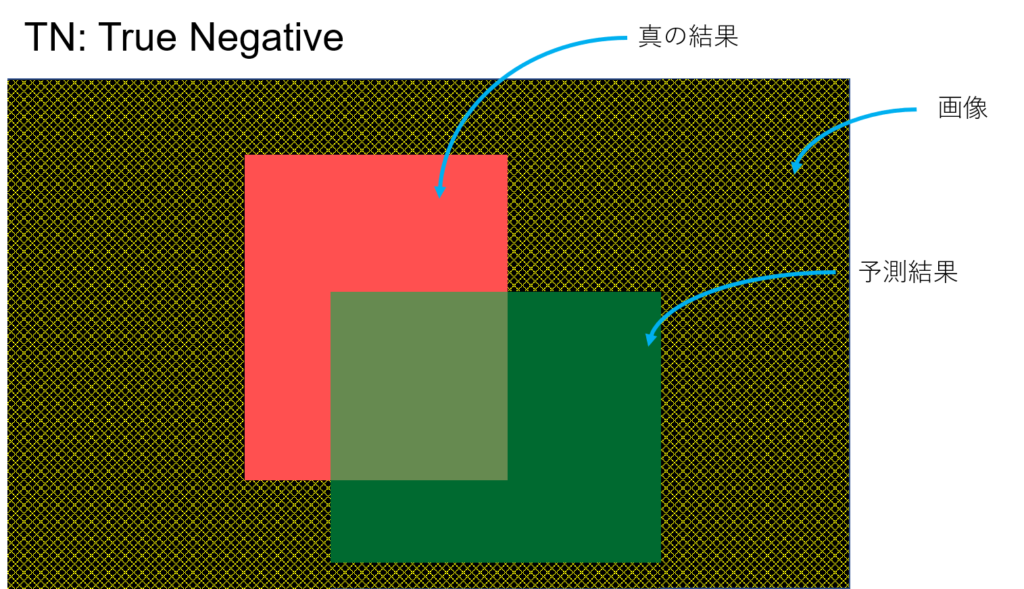
負(Negative)であるといったけど、それは合っている(True)。
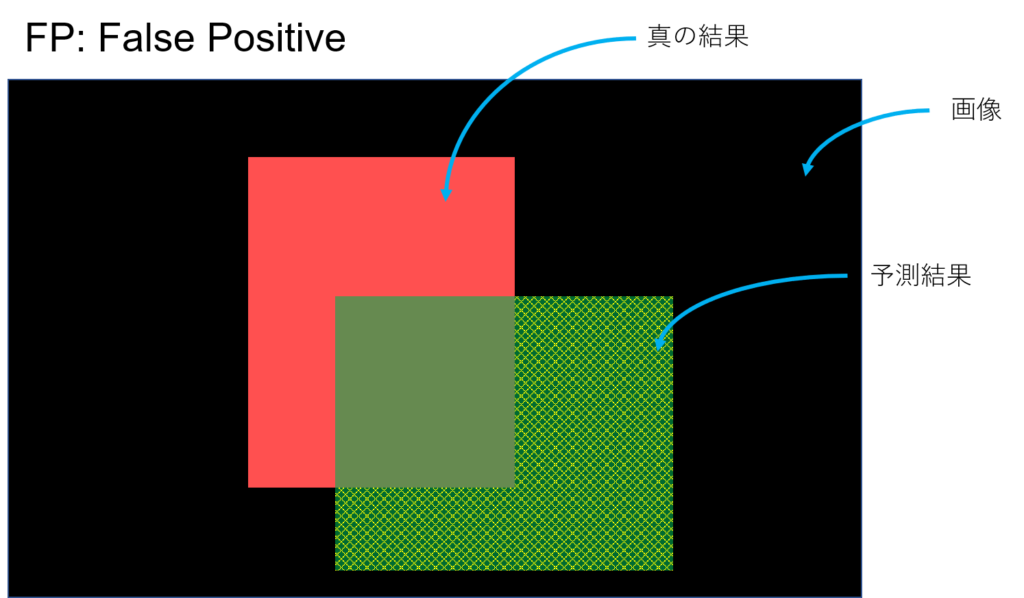
正(Positive)であるといったけど、それは間違ってて(False)本当は負である。
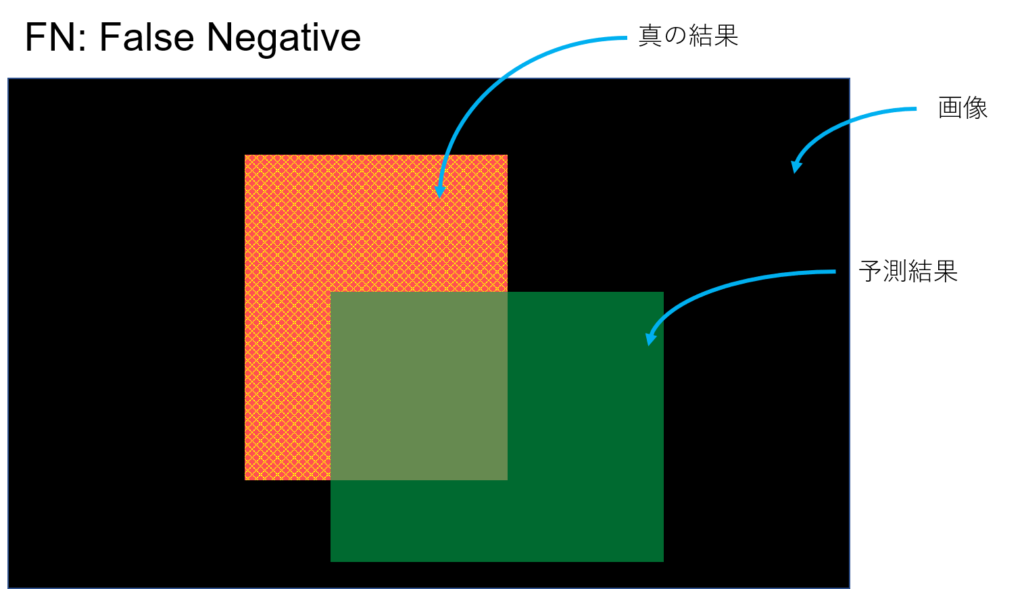
負(Negative)であるといったけど、それは間違ってて(False)本当は正である。
Accuracy, Precision, Recall, IoU
画像処理ではaccuracyは殆ど使われませんね。まぁ一応。
Accuracy: 予測領域全体の内の正解の割合
$$Accuracy = \frac{TP+TN}{TP+TN+FP+FN}$$
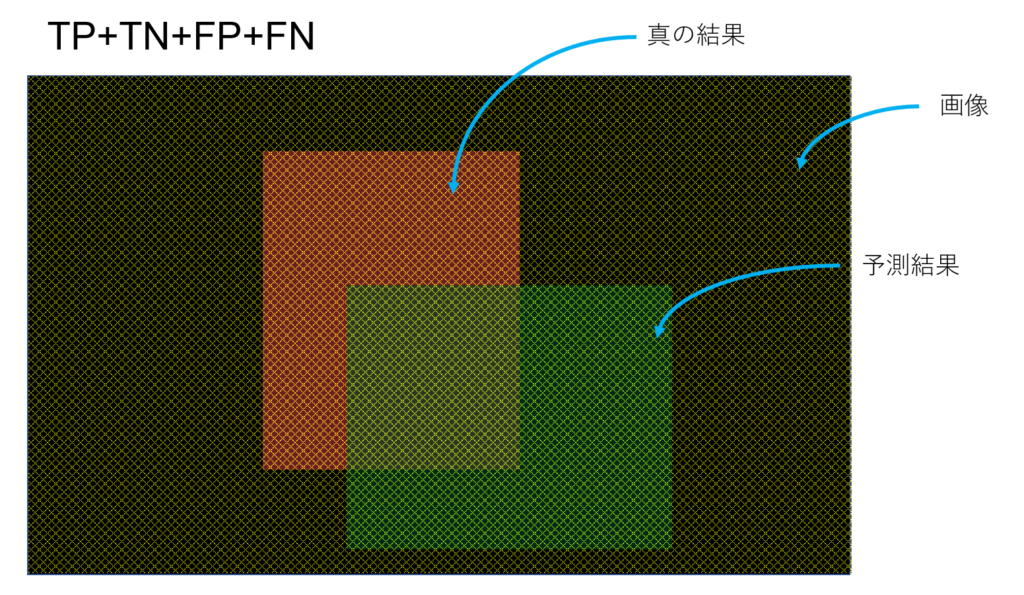
この領域の内、
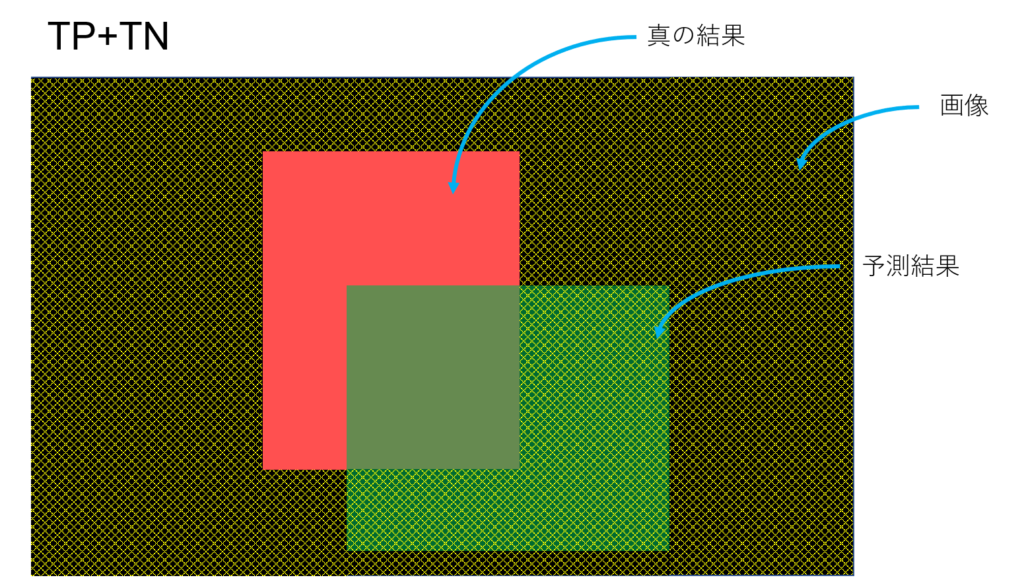
この領域が示す割合がAccuracy。画像処理タスクではAccuracyを計算しても評価として微妙。真の結果の領域が狭ければAccuracyが高く出てしまう傾向にあるので、その機械学習結果が本当に上手くできているのか不明になってしまう。
Precision: 予測結果が正の領域(緑)の内の正解の割合
$$Precision = \frac{TP}{TP+FP}$$
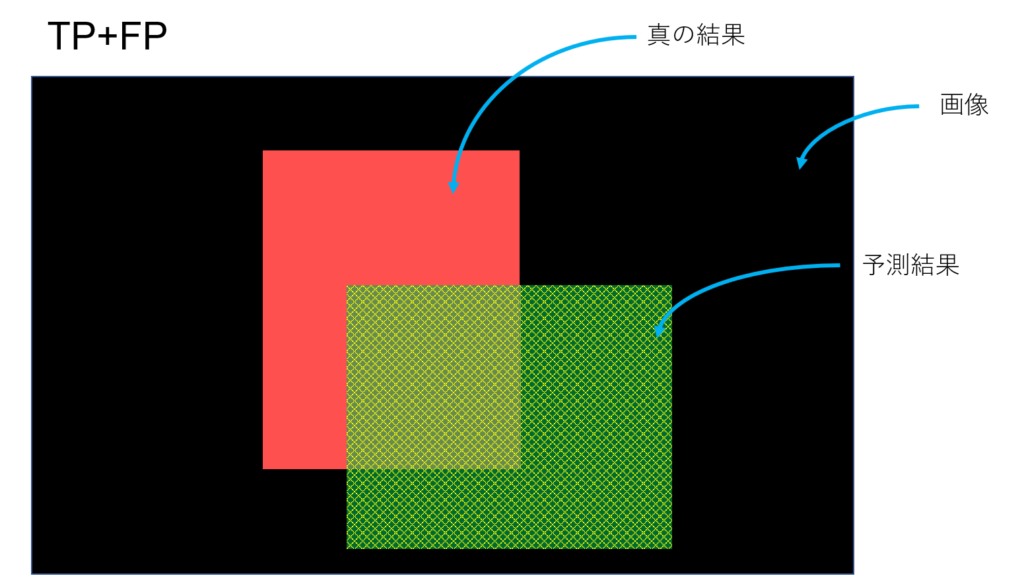
この領域の内、
この領域が占める割合。
セグメンテーションタスクでは,Precisionが高いと信頼度の高い領域しか選ばれないモデルであると定性的な見方ができる(と思う。)
真の結果が漏れなく選ばれているとは言っていない。(それを見るのはRecall)ほんの少ししか選ばれてなくても、それが真の結果がとマッチするならPrecisionは高く出る。
物体検出タスクでは,予測結果のバウンディングボックスが小さければPrecisionも高くでる傾向にある。真の結果と予測結果がマッチしてるのかよくわからないため、あまり使われているのを見ない。
Recall: 真の結果が正である領域(赤)のうち、正解である領域
$$Recall = \frac{TP}{TP+FN}$$
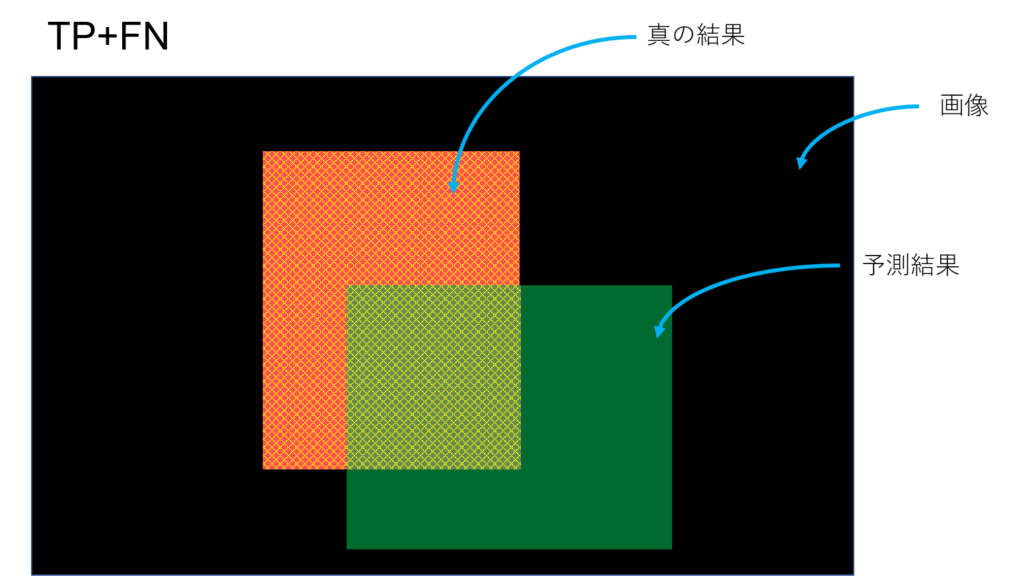
この領域の内、
この領域が占める割合。
セグメンテーションタスクでは,Recallが高いと真の結果である領域は殆ど選んでいるモデルであると定性的な見方ができる(と思う)
間違って負の領域を正といってしまう領域(FP)が多いかもしれない。(それを見るのはPrecision)
Precisionが低くてRecallが高いと、間違ってもいいから(FPでもいいから)とにかく真の結果を正とするようなモデルであると言える。
物体検出タスクでは,画像全体を正と予測してしまえばRecallは最大になるので、単純に評価に使うのは。。。
Precision-Recall curveについて
Precision, Recallを同時にみる事でモデルの性格を見ることができる。信頼度によって正か負かを決めるのだが、そのthresholdを低くするか高くするかでPrecision, Recallが変わる。thresholdを動かしてPrecision-Recallのグラフを描く事がよくある。(Precision-Recall curve, 参考)
PrecisionもRecallも高いほうが良いので、Precision-Recall curveの面積が大きいほうがモデルの性能が良い。
F値
あと、precision, recallの両方を合わせてみる指標としてF値がある。Precision, Recallの調和平均。
$$F value = \frac{2 \times Recall \times Precision}{Recall + Precision}$$
IoU: 真の結果とのマッチ度
$$IoU=\frac{TP}{TP+FP+FN}$$
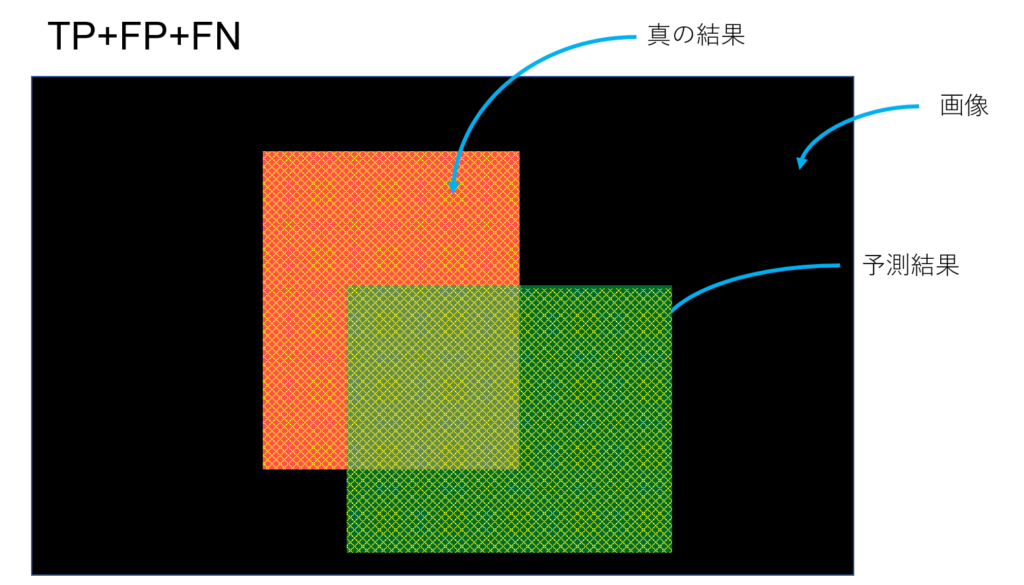
この領域の内、
この領域が占める割合。
ディープラーニング関係の評価でよく見るやつ。PrecisionとRecallではよくわからなかった予測結果と真の結果の重なり具合(漏れ具合)を評価できる指標。単純に、IoUが高ければよく漏れなく間違いなく予測できていて、低ければ間違い多い。
追記:こんどmAPについても書く(-_-)/~~~ピシー!ピシー!
いつも頭の中でイメージする図を描きました!ごちゃごちゃにならないくなるといいな((+_+))以上です!(^^)!
2 Responses
とても参考になりました。
ただ、Accuraryの説明にあるTP+TNの画像が間違っていると思います。
本当だ、、、確認したら間違ってますね
ありがとうございます!